围棋胜负判定 :以围棋胜负来判定人工智能高低能否可行?
先给一个肯定的回答,就目前人工智能的发展来说,如果以围棋的胜负来判定其能力的高低是可行的。咱们可以先看1997年IBM公司的人工智能“深蓝”,它在国际象棋上击败了国际象棋大师卡斯帕罗夫。

根据这位大师的回忆,在1985年的时候,他战胜阿纳托利·卡尔波夫之后成为世界国际象棋冠军。在那一年,他在德国汉堡与世界上最先进的32台象棋电脑展开了一场车轮战。比赛结果全盘获胜。然而,仅仅12年后的1997年,大师需要拼尽全力对战一台计算机,当时的《新闻周刊》把这场比赛称为“人脑的最后防线”。那一年象棋计算机在科技的加持下,实力大增;而大师正好又是国际象棋冠军,于是代表全人类与机器进行了那场至今仍然家喻户晓的对决。他与IBM“深蓝”计算机下了两盘棋,一胜一败。
大师将计算机的胜利归功于“深蓝”计算机的创造者,许峰雄(电脑“深蓝”的设计者,出生于中国台湾,毕业于台湾大学和卡内基·梅隆大学),并向他和他的团队由衷致敬。因为机器的胜利也是人类的胜利(因为人类是机器的缔造者),当时的“深蓝”能够在一秒钟内分析出惊人的200万个棋位。
但那个时候有人说,围棋是人工智能无法攻克的壁垒,是因为围棋计算量实在是太大了。选择围棋除了这个,还有一个原因。1、对于计算机来说,每一个位置都有黑、白、空三种可能,那么棋盘对于计算机来说就有3的361次方种可能,而宇宙的原子只有10的80次方。下图是围棋的复杂程度卷积。

但令人震惊的是在2016年3月份,Alpha Go以4-1的比分击败李世石。而Alpha Go 的算法也不是穷举法,而是在人类的棋谱中学习人类的招法,不断进步,就是我们说的机器学习。而它在后台,进行的则是胜率的分析,这跟人类的思维方式有很大的区别,它不会像人类一样计算目数,而是胜率,它会将对手的信息和招式完全记录下来,如果对手没有新的招式来应对,输的概率是非常之大。
2、围棋作为一种开启智力的“游戏”,已有3000多年的历史,人机对弈也有近50年历史。《大英百科全书》中说:“围棋,公元前2356年起源于中国。” 自古以来,围棋备受帝王、将军和知识分子、神童的喜爱,在国外包括爱因斯坦、约翰纳什和图灵等都是围棋的爱好者。围棋的英文就是“Go”,所以人家其实不叫阿尔法狗(只是咱们中文的谐音),真正的叫法是阿尔法围棋。
阿尔法围棋有哪些特别之处?阿尔法围棋是一个中央处理器(Central Process Unit,CPU)和图形处理器(Graphic Process Unit,GPU)一起工作的围棋智能机器人。
阿尔法围棋以神经网络、深度学习、蒙特卡洛树搜索法为核心算法。系统由四部分组成:1、策略网络(Policy Network),以当前局面为输入,预测下一步的走法;
2、快速走子(Fast Rollout),目标和策略网络相似,在适当牺牲质量的条件下的加速走法;
3、价值网络(Value Network),以当前局面为输入,估算胜率。
4、蒙特卡洛树搜索(Monte Carlo Tree Search),把上述三个部分整合起来,形成完整的系统。
早期的阿尔法狗有176个GPU和1202个CPU。GPU能够通过内部极多进程的并行运算,取得比CPU高一个数量级的运算速度。
阿尔法围棋(AlphaGo)是通过两个不同神经网络“大脑”合作来改进下棋。这些“大脑”是多层神经网络,跟那些Google图片搜索引擎识别图片在结构上是相似的。它们从多层启发式二维过滤器开始,去处理围棋棋盘的定位,就像图片分类器网络处理图片一样。经过过滤,13个完全连接的神经网络层产生对它们看到的局面判断。这些层能够做分类和逻辑推理。第一大脑:落子选择器 (Move Picker)
阿尔法围棋(AlphaGo)的第一个神经网络大脑是“监督学习的策略网络(Policy Network)” ,观察棋盘布局企图找到最佳的下一步。事实上,它预测每一个合法下一步的最佳概率,那么最前面猜测的就是那个概率最高的。这可以理解成“落子选择器”。
第二大脑:棋局评估器 (Position Evaluator)
阿尔法围棋(AlphaGo)的第二个大脑相对于落子选择器是回答另一个问题,它不是去猜测具体下一步,而是在给定棋子位置情况下,预测每一个棋手赢棋的概率。这“局面评估器”就是“价值网络(Value Network)”,通过整体局面判断来辅助落子选择器。这个判断仅仅是大概的,但对于阅读速度提高很有帮助。通过分析归类潜在的未来局面的“好”与“坏”,阿尔法围棋能够决定是否通过特殊变种去深入阅读。如果局面评估器说这个特殊变种不行,那么AI就跳过阅读。
阿尔法围棋(AlphaGo)此前的版本,结合了数百万人类围棋专家的棋谱,以及强化学习进行了自我训练。后来它又有了个弟弟AlphaGoZero,其能力则在这个基础上有了质的提升。最大的区别是,它不再需要人类数据。也就是说,它一开始就没有接触过人类棋谱。研发团队只是让它自由随意地在棋盘上下棋,然后进行自我博弈。
据阿尔法围棋团队负责人大卫·席尔瓦(Dave Sliver)介绍,AlphaGoZero使用新的强化学习方法,让自己变成了老师。系统一开始甚至并不知道什么是围棋,只是从单一神经网络开始,通过神经网络强大的搜索算法,进行了自我对弈。随着自我博弈的增加,神经网络逐渐调整,提升预测下一步的能力,最终赢得比赛。更为厉害的是,随着训练的深入,阿尔法围棋团队发现,AlphaGoZero还独立发现了游戏规则,并走出了新策略,为围棋这项古老游戏带来了新的见解。
一个大脑:AlphaGoZero仅用了单一的神经网络。AlphaGo用到了“策略网络”来选择下一步棋的走法,以及使用“价值网络”来预测每一步棋后的赢家。而在新的版本中,这两个神经网络合二为一,从而让它能得到更高效的训练和评估。
神经网络:AlphaGoZero并不使用快速、随机的走子方法。在此前的版本中,AlphaGo用的是快速走子方法,来预测哪个玩家会从当前的局面中赢得比赛。相反,新版本依靠地是其高质量的神经网络来评估下棋的局势。

相关文章
-
微商客户资源(微商货源网精准客源)详细阅读

微商找客源是对微商来说非常重要的一件事,很多做微商的就是苦苦支撑着因为没有客源,微商如何找客源一直是一个不衰的话题,下面我们就来讨论下这个话题。一:定...
2022-09-08 18969
-
什么是AR(什么是ar导航)详细阅读

增强现实的AR互动营销增强现实的AR互动营销一款叫做《口袋妖怪GO》的手游在欧美火了,在还未上线的中国,#PokemanGo#这一话题的微博阅读量已经...
2022-09-08 18229
-
弯弯的月亮像小船(弯弯的月亮像小船,小小的船儿两头尖)详细阅读

点击上方蓝字关注我们你拍一,我拍一,一个小孩坐飞机。你拍二,我拍二,两个小孩丢手绢。你拍三,我拍三,三个小孩来搬砖。你拍四,我拍四,四个小孩写大字。你...
2022-09-08 13654
-
流苏是什么(流苏是什么样子的图片)详细阅读

导语 听说流苏和秋天更配哦!流苏这个元素也不是今时今日才流行起来的,能经久不衰是因为它真的美呆了~踏进9月,秋高气爽,随风摇曳的流苏真心是风情万种!宝...
2022-09-08 642
-
淘口令是什么意思(什么叫做淘口令)详细阅读
现在开淘宝的越来越多了。但是做得好的好的始终还是那么多,好多人因为刚开始很迷茫,不知道怎么做,或者做到一半发现没有效果,无奈之下只好放弃了,我作为一个...
2022-09-08 667
-
发家致富网(发财致富网)详细阅读

前言:面相五行人格与性格职业密切相关,有什么用的性格就有什么样的命运,性格决定命运。有些人需要白手起家获得财富,有些人则有可能会发横财,你会通过什么方...
2022-09-08 644
-
兼职在家工作(在家工作的兼职)详细阅读

力哥说理财,简单又好玩。跟着力哥走,理财不用愁!本文3100字,阅读约6分钟我要介绍的赚钱工作就是兼职写稿赚稿费。主业靠写作发大财是件非常困难的事,只...
2022-09-08 660
-
系统流程图(系统流程图是描述)详细阅读
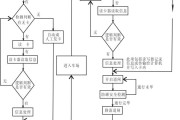
数据流程图(简称DFD)是一种能全面地描述信息系统逻辑模型的主要工具。简言之,就是以图形的方式来描述数据在系统流程中流动和处理的移动变换过程,反映数据...
2022-09-08 622




发表评论